Implementing Tasks
In AxoPy, the individual components of an experiment are tasks. In essence, a task does any or all of the following:
Takes in data from previous tasks (read)
Streams data from a data acquisition device (daq)
Processes the streaming or task data (proc)
Draws things to the screen (ui)
Outputs data of its own (write)
One example of a task is the Oscilloscope which we saw on the previous
page. It is responsible for streaming data from a data acquisition device (daq)
and displaying it in a dynamic plot (ui). The purpose of this task is usually
just to allow the researcher to visually verify the integrity of the data
coming in from the device before proceeding with the rest of the experiment.
Another example of a task is a cursor control task (subject produces input in
attempt to hit targets on the screen). This kind of task reads in and processes
data from an input device (daq), displays some information on screen to give
feedback to the subject (ui), and records some data for post-experiment analysis
(write). It may also require some calibration parameters from a previous task
(read). This is a fairly complex task with an enormous number of possible
implementations, so there’s no built-in CursorControlTask.
There isn’t really a strict definition of what a single task is or what it should or shouldn’t do, but it’s a good idea to make tasks as simple as possible — any given task should do just a couple things and do them well. This encourages modularity so you can re-use task implementations in different experiments, etc.
In terms of the AxoPy API, a task looks like the following:

In this part of the user guide, we’ll go through how to make each of the four connections in the diagram and refer to separate documents for the details of working with those four components.
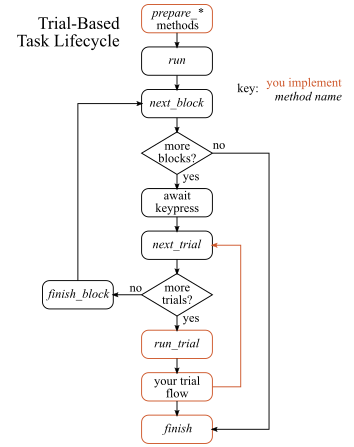
The Task Lifecycle
AxoPy experiments are event-driven, following the way graphical user interface
frameworks tend to operate. This can be an unfamiliar way of writing programs,
so it’s important to understand the overall idea before seeing some of the
details. Tasks in an experiment all go through the same lifecycle, shown below.
First, the Task instances are created (by you) and then they’re handed
off to an Experiment, like we saw in the previous
section:
exp = Experiment(...)
exp.run(Oscilloscope())
Once you call run(), the
Experiment collects the task objects passed in, sets up the shared resources
(data storage, data acquisition, graphical backend), then proceeds to prepare
and run each task in sequence. That means pretty much all of the functionality
of the experiment is defined in the Task classes.
The most important thing to understand about tasks is that they’re written by
defining what should happen in response to certain events. For example, the
Oscilloscope task defines a method that gets called every time there
is new data available from the data acquisition stream, allowing it to update
the signals displayed on the screen. This is sometimes referred to as
a callback. You can think of the Experiment as running an infinite loop
checking for events that occur, then dispatching the data from those events to
the task if appropriate.
There are a standard set of methods that are automatically run by the
Experiment the task belongs to, and you can
optionally implement these methods to make use of the shared resources that the
Experiment manages. These are the prepare
methods: prepare_design, prepare_storage, prepare_input_stream, and
prepare_graphics.
Say you’re writing a task that makes use of data storage only (read and write).
A common example of this is processing some data to make it suitable for other
tasks later on in the experiment. To interact with the storage functionality
set up by the Experiment, your class should implement the
Task.prepare_storage() method. If you click on the link to the API
documentation for that method, you’ll see that
a Storage object is passed into this method, which is
provided by the Experiment. We’ll see more details about setting up storage
specifically later on, but for the sake of the example, it’s sufficient to
point out that the storage object lets you create reader and/or writer objects
that you can save for use later on in your task:
from axopy.task import Task
class MyTask1(Task):
def prepare_storage(self, storage):
# here's where we can use the storage object to read data from other
# tasks or write our own data to storage
The Task.prepare_design() is slightly different from the others in that
it’s not actually for setting up a shared resource. It’s actually just an
opportunity for your task to build a Design so
that it can easily be written in terms of a series of repeated trials.
After the rest of the prepare methods are called, the Task.run()
method is called. This is where your task should set up its own events and
start running. In “experiment tasks” (those implementing prepare_design),
the flow of the task proceeds through it’s Design by calling
Task.next_trial`.
There are two main ways for a task to end. One is by calling
Task.finished() somewhere in your task implementation. This signals to
the Experiment that the task is done, then the
Task.finish() method is called so you can clean up anything you need to
before the next task runs. A common example of cleanup is to make sure the
DAQ is stopped.
The flowchart below shows the lifecycle of a Task when it’s run by an
Experiment.